xo / xo Goto Github PK
View Code? Open in Web Editor NEWCommand line tool to generate idiomatic Go code for SQL databases supporting PostgreSQL, MySQL, SQLite, Oracle, and Microsoft SQL Server
License: MIT License
Command line tool to generate idiomatic Go code for SQL databases supporting PostgreSQL, MySQL, SQLite, Oracle, and Microsoft SQL Server
License: MIT License
I have a target database with column and table table with colons and the generated types look like:
// Account:order represents a row from public.account:order.
type Account:order struct {
Session:id string // session:id
Session:type sql.NullString // session:type
Session:brandSlug string // session:brand_slug
Session:created sql.NullInt64 // session:created
Event:id string // event:id
...
}
One idea would be to title case the identifiers using illegal characters as word boundaries then using struct tags to indicate the column names and providing a constant for the table name:
const AccountOrderTable = "account:order"
type AccountOrder struct {
SessionId string `xo:"session:id"`
SessionType sql.NullString `xo:"session:type"`
SessionBrandSlug string `xo:"session:brand_slug"`
SessionCreated sql.NullInt64 `xo:"session:created"`
EventId string `xo:"event:id"`
...
}
I suppose it would be nice to add - --custom-types-package-import-line.
For example I have been generating models from my rails app and there is an Inet Type. --custom-types-package property subbed unimplemented types but failed to import the package. I can deal with unsupported types by adding a file to models directory with package 'models' which will cover unsupported types and it seems a little bit more elegant in lieu of import("appname/xocustom") ...
Tables with multiple foreign keys that point to the same foreign table result in naming collisions.
A simplified schema of what I'm working with:
CREATE TABLE "address" (
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"name" text NOT NULL
);
CREATE TABLE "mail" (
"id" integer NOT NULL PRIMARY KEY AUTOINCREMENT,
"sender_id" integer NOT NULL,
"recipient_id" integer NOT NULL,
FOREIGN KEY ("recipient_id") REFERENCES "address" ("id"),
FOREIGN KEY ("sender_id") REFERENCES "address" ("id") ON DELETE NO ACTION ON UPDATE NO ACTION
);
CREATE INDEX "idx_mail_recipient_id" ON "mail" ("recipient_id");
CREATE INDEX "idx_mail_sender_id" ON "mail" ("sender_id");mail.xo.go ends up containing this:
// Address returns the Address associated with the Mail's RecipientID (recipient_id).
//
// Generated from foreign key 'mail_recipient_id_fkey'.
func (m *Mail) Address(db XODB) (*Address, error) {
return AddressByID(db, m.RecipientID)
}
// Address returns the Address associated with the Mail's SenderID (sender_id).
//
// Generated from foreign key 'mail_sender_id_fkey'.
func (m *Mail) Address(db XODB) (*Address, error) {
return AddressByID(db, m.SenderID)
}I'd like to suggest naming those functions differently. How about using the column name without _id? e.g. Recipient() and Sender()? or maybe even combine it with the table name: RecipientAddress() and SenderAddress()?
Unless of course I'm missing something. I could probably copy the templates and modify them for now, but I'd rather see this fixed :)
Given the following schema, a struct is created with a method name matching a property name.
CREATE TABLE `fragment` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`fragment` VARCHAR(100) NOT NULL,
`fragment_id` BIGINT NOT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;
ALTER TABLE `fragment` ADD CONSTRAINT `fragment_fragment_unique` UNIQUE (`fragment`);
ALTER TABLE `fragment` ADD CONSTRAINT `fragment_fragment_id_fk` FOREIGN KEY (`fragment_id`) REFERENCES `fragment` (`id`) ON DELETE CASCADE ON UPDATE CASCADE;
Apparently it's the foreign key to the table of the same name.
// Fragment represents a row from 'dbname.fragment'.
type Fragment struct {
ID int64 `json:"id"` // id
Fragment string `json:"fragment"` // fragment
FragmentID int64 `json:"fragment_id"` // fragment_id
// xo fields
_exists, _deleted bool
}
// Fragment returns the Fragment associated with the Fragment's FragmentID (fragment_id).
//
// Generated from foreign key 'fragment_fragment_id_fk'.
func (f *Fragment) Fragment(db XODB) (*Fragment, error) {
return FragmentByID(db, f.FragmentID)
}
Perhaps rather than adding logic for this, there should just be a warning about columns that match the name of the table when using foreign keys. Doesn't seem like a common use case.
Sorry to open another issue while we are still working on the first, but I wanted to mention something I noticed as well.
I generated the models without issue using "xo"
I noticed it created this "UUID" type.
But I don't see it imported???
Not sure if this is by design or my mistake.
Thanks.
package models
// GENERATED BY XO. DO NOT EDIT.
import (
"database/sql"
"errors"
)
// VUser represents a row from public.v_users.
type VUser struct {
UserUUID UUID // user_uuid
DomainUUID UUID // domain_uuid
Username sql.NullString // username
Password sql.NullString // password
Salt sql.NullString // salt
ContactUUID UUID // contact_uuid
UserStatus sql.NullString // user_status
APIKey UUID // api_key
UserEnabled sql.NullString // user_enabled
AddUser sql.NullString // add_user
AddDate sql.NullString // add_date
// xo fields
_exists, _deleted bool
}
I know most often we should put all tables in the same DB, but I do have a case to deal with different DBs in the same project, because the content in each DB is totally irrelevant to other DBs.
How to deal with Multi-DBs in the same project? Can they co-exist in the same models folder? Or, I have to use -o to generate them into different model folders? The latter is something I want to avoid. Thx.
The code generated for the Insert() function assumes that that the primary key is auto increment and does not insert it and uses LastInsertId to set it.
i generated a model from a postgres db. the struct had a line that looked similar to this:
MyColumnText JSON json:"my_column_text" // my_column_text
but when building the application JSON was undefined. is there an expectation that i would have already handled this type on my own or am i missing something with regard to using xo?
to use the new template trimming functionality
CREATE OR REPLACE FUNCTION public.void_return(
) RETURNS void LANGUAGE plpgsql STRICT AS $$
BEGIN
RAISE NOTICE 'this function returns nothing';
END;
$$;generates:
// VoidReturn calls the stored procedure 'public.void_return() void' on db.
func VoidReturn(db XODB) (Void, error) {
var err error
// sql query
const sqlstr = `SELECT public.void_return()`
// run query
var ret Void
XOLog(sqlstr)
err = db.QueryRow(sqlstr).Scan(&ret)
if err != nil {
return Void{}, err
}
return ret, nil
}which fails to build with: models/sp_voidreturn.xo.go:7: undefined: Void
Hi, I'm having problems generating code for a database with multiple schemas. Consider the following example:
CREATE TABLE asset(
id SERIAL PRIMARY KEY,
name VARCHAR(10)
);
CREATE SCHEMA clientx;
CREATE TABLE clientx.asset(
asset_id INT REFERENCES asset,
special_property BOOLEAN
);We use this pattern to keep additional fields for some customers.
I ran xo using the flag -s twice (xo $PGURL -s public -s clientx -o .), but I got error: could not find col, refTpl, or refCol. Is this supported?
BTW: very useful project :)
Hi. I was testing out your package and either did something wrong or found a bug:
$ go run main.go
2016/05/28 12:12:26 main.go:31: sql: Scan error on column index 1: unsupported Scan, storing driver.Value type []uint8 into type *time.Time
exit status 1
To reproduce, use the following mysql schema:
CREATE TABLE `some_table` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`some_int` int(11) NOT NULL,
`some_nullable_int` int(11) DEFAULT NULL,
`some_string` varchar(100) NOT NULL,
`some_nullable_string` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=54 DEFAULT CHARSET=utf8;
Generate the schema: xo mysql://root@localhost/allthethings -o models
and run the following main (note, obviously use your own model dir):
package main
import (
"database/sql"
"log"
_ "github.com/go-sql-driver/mysql"
"< PATH TO MODEL>"
)
func main() {
log.SetFlags(log.LstdFlags | log.Lshortfile)
db, err := sql.Open("mysql", "root@tcp(localhost:3306)/allthethings")
if err != nil {
log.Fatal(err)
}
err = db.Ping()
if err != nil {
log.Fatal(err)
}
st := models.SomeTable{SomeString: "foo"}
err = st.Insert(db)
if err != nil {
log.Fatal(err)
}
// the following line errors
results, err := models.SomeTablesBySomeString(db, "foo")
if err != nil {
log.Fatal(err)
}
for _, r := range results {
log.Printf("Found id %d", r.ID)
}
log.Println("complete")
}
The error happens at results, err := models.SomeTablesBySomeString(db, "foo").
The entry in pg_index for a postgresql functional index has indkey=0, leading to NULL results from the PgIndexColumns query:
error: sql: Scan error on column index 1: converting driver.Value type <nil> ("<nil>") to a int: invalid syntax
Adding i.indkey <> '0' AND to the where clause in both PgIndexColumns and PgTableIndexes seems to be the right fix.
(I'd do this as a pull request, but I don't have databases in place to test the go generate step).
I looked through the command line options and I didn't see this feature, is this something that is implemented or that you plan to implement? If not, would you consider accepting a pull request with this functionality?
In the example you have this:
const (
// FictionBookType is the book_type for 'FICTION'.
FictionBookType = BookType(1)
// NonfictionBookType is the book_type for 'NONFICTION'.
NonfictionBookType = BookType(2)
)But I prefer the generated names to be:
const (
// BookTypeFiction is the book_type for 'FICTION'.
BookTypeFiction = BookType(1)
// BookTypeNonfiction is the book_type for 'NONFICTION'.
BookTypeNonfiction = BookType(2)
)I think this will make them easier to find through an IDE. And more in line with go std lib like https://golang.org/src/net/http/status.go
Is this possible?
Hi. Any suggestions on how to handle marshaling JSON data into structures created by xo?
For example, I have the following table:
create table projects (
id varchar(40) primary key default gen_random_uuid(),
project_name varchar(256),
docker_image_name varchar(256),
project_homepage text,
project_tags text,
project_description text,
publisher_id varchar(40),
featured varchar(5) default 'false'
);
xo generates this structure:
type Project struct {
ID string `json:"id"` // id
ProjectName sql.NullString `json:"project_name"` // project_name
DockerImageName sql.NullString `json:"docker_image_name"` // docker_image_name
ProjectHomepage sql.NullString `json:"project_homepage"` // project_homepage
ProjectTags sql.NullString `json:"project_tags"` // project_tags
ProjectDescription sql.NullString `json:"project_description"` // project_description
PublisherID sql.NullString `json:"publisher_id"` // publisher_id
Featured sql.NullString `json:"featured"` // featured
// xo fields
_exists, _deleted bool
}
I'm trying to marshal this json data (from a POST request I'm making) into a structure:
{
"ID": "1234",
"ProjectName": "test projects",
"ProjectAuthor": "odewahn",
"GitOrigin": "www.example.com",
"DockerhubPullCommand": "project",
"ProjectDescription": "this is a great projects",
"ProjectTags": "test data",
"Featured": "false"
}
Using this command:
var project models.Project
err := json.Unmarshal(dat, &project)
The problem I'm having its that the Marshal doesn't seem to work with these structures, or throws an error like
json: cannot unmarshal string into Go value of type sql.NullBool
I would appreciate any ideas or suggestions!
Hi,
I know Microsoft SQL Server are now supported in Linux, but I need the xo executable under Microsoft Windows. Can you build a xo binary release for Microsoft Windows please?
I tried it myself but found it is too much a mouthful for me:
...\Go\src\github.com\knq\xo>go build -v
github.com/alexflint/go-arg
github.com/knq/dburl
github.com/gedex/inflector
github.com/knq/snaker
github.com/knq/xo/models
github.com/knq/xo/templates
golang.org/x/net/context
github.com/go-sql-driver/mysql
github.com/denisenkom/go-mssqldb
github.com/lib/pq/oid
github.com/lib/pq
github.com/knq/xo/internal
github.com/mattn/go-sqlite3
# github.com/mattn/go-sqlite3
exec: "gcc": executable file not found in %PATH%
Have you ever built a xo executable under Microsoft Windows? If doing a binary release is too much a hassle, can you put the executable somewhere that I can grab please? Thanks!
Hi, I have a question.
Why is this library using *time.Time for not null column? It seems like pq.NullTime is for nullable time column when transforming table to struct.
CREATE OR REPLACE FUNCTION public.fake_trigger(
) RETURNS trigger LANGUAGE plpgsql AS $$
BEGIN
RETURN NEW;
END;
$$;generates:
// FakeTrigger calls the stored procedure 'public.fake_trigger() trigger' on db.
func FakeTrigger(db XODB) (Trigger, error) {
var err error
// sql query
const sqlstr = `SELECT public.fake_trigger()`
// run query
var ret Trigger
XOLog(sqlstr)
err = db.QueryRow(sqlstr).Scan(&ret)
if err != nil {
return Trigger{}, err
}
return ret, nil
}which fails to build with models/sp_faketrigger.xo.go:7: undefined: Trigger
Running xo with mysql:// and I got the following error (this is the entire error):
error: template: mysql.type.go.tpl:1: illegal number syntax: "-"
I'm not familiar with Go templates, so I'm at a loss for debugging. Any suggestions?
(BTW, I'm super pumped for this project. It looks like exactly what I want.)
Go defines the zero value for strings to be an empty string, so there is no way to test if the value has been set to empty, or was simply empty from the beginning without tracking each set on the struct properties.
How should we handle columns that do not allow null values, but should also not allow empty values for structs that have strings as the column type?
type Person struct {
ID int64 `json:"id"` // id
Name string `json:"name"` // name
_exists, _deleted bool
}
...
p = models.Person{}
err = p.Save(db) // <-- Should not have worked since struct is empty and person.name does not allow null values
if err != nil {
fmt.Println(err)
}
fmt.Println("Person.ID, p.ID)
I can manually edit all the models but surely more people need "" == nil in this case than not.
See also sql.NullString.
Hi, just a quick question: why does xo truncates the db name when it ends with an 's'.
e.g. db name: sms --> sm.xo file
Is there any specific reason for this? And is there a way to force xo to keep the 's'?
Thank you!
Here is my test schema
CREATE TABLE user (
user_id TEXT NON NULL PRIMARY KEY,
email TEXT,
first_name TEXT,
last_name TEXT,
headline TEXT,
profile_url TEXT,
location TEXT,
username TEXT,
password TEXT
);
CREATE TABLE id_provider
(
provider_id TEXT NOT NULL,
user_id TEXT NOT NULL REFERENCES user( user_id ),
network TEXT,
PRIMARY KEY( provider_id, user_id )
);
If I remove the PRIMARY KEY table constraint it generates fine. With it the following error is generated
error: sql: Scan error on column index 5: sql/driver: couldn't convert 2 into type bool
Would it be possible to support composite primary keys? I need them for the project I'm working on and would like to use xo to save me some time. If not is there some sort of work around where I can still generate most of code using xo.
Regards and thanks for making this work public.
Let me start by saying that I'm thrilled with the work being done on this utility.
I see XO as being an integral part of bootstrapping web applications written in GO,
and I'd love to see how it continues to grow.
Unfortunately I'm having a problem.
I've got a schema for MySQL 5.5.46 (which I've attached),
which had fallen victim to Issue #3
I went through and removed indexes until XO was able to run completely.
The generated code had a couple issues.
First, some of the (table)ByID methods were defined like this:
func ArtistByID(db XODB, iD int64, iD int64, iD int, iD int64, iD int64, iD int64, iD int64, iD int64)(*Artist, error) {...}
There were also a couple of tables which didn't have a (table)ByID method generated.
I haven't really dug into this, I will when I have a chance tomorrow.
db_init.txt
I get the error described in the header when I try to run xo against my MySQL schema. Is there any flags/env vars to print debug info, e.g. so I could finding out which query that crashes it?
I found:
http://stackoverflow.com/questions/12597620/1242-subquery-returns-more-than-1-row-mysql
which might be related to the issue.
Running xo and/or any of the examples yields the following traceback:
panic: template: postgres.idx.go.tpl:16: illegal number syntax: "-"
goroutine 1 [running]:
text/template.Must(0x0, 0x688028, 0xc82016e220, 0x0)
/usr/local/Cellar/go/1.5.1/libexec/src/text/template/helper.go:23 +0x4b
github.com/knq/xo/templates.init.1()
/go/src/github.com/knq/xo/templates/templates.go:253 +0x36c
github.com/knq/xo/templates.init()
/go/src/github.com/knq/xo/templates/types.go:72 +0x112a
github.com/knq/xo/loaders.init()
/go/src/github.com/knq/xo/loaders/postgres.go:720 +0x79
main.init()
/go/src/github.com/knq/xo/xo.go:271 +0x7e
goroutine 17 [syscall, locked to thread]:
runtime.goexit()
/usr/local/Cellar/go/1.5.1/libexec/src/runtime/asm_amd64.s:1696 +0x1
Is this dependent on new text/template features in Go 1.6?
"q.Scan undefined (type Queue has no field or method Scan)"
If the table name is such that shortname is "q" that clashes with the use of "q" to hold the result of db.Query in code generated from postgres.query.go.tpl.
(Changing "q" to "_q" in a local copy of the template used with --template-path works around it easily enough.)
xo generate the following postgres types as int64:
This behaviour will rise the following error:
sql: Scan error on column index 0: converting driver.Value type time.Time ("2016-09-17 15:35:37.816458 +0000 +0000") to a int64
Based on github.com/lib/pq driver, those should be of type time.time or pq.NullTime:
func main() {
db, err := sql.Open("postgres", "dbname=test01 user=postgres host=localhost sslmode=disable")
if err != nil {
log.Fatal(err)
}
pgtypes := []string{
"date",
"timestamp without time zone",
"timestamp with time zone",
"time without time zone",
"time with time zone"}
for _, t := range pgtypes {
v := new(interface{})
rows, _ := db.Query(fmt.Sprintf("SELECT $1::%v", t), "2013-01-04 20:14:58.80033")
// row.Scan(v)
rows.Next()
c, _ := rows.Columns()
rows.Scan(v)
fmt.Printf("Go: %T\tPG: %-30v PG-Short: %v\n", *v, t, c[0])
}
}Go: time.Time PG: date PG-Short: date
Go: time.Time PG: timestamp without time zone PG-Short: timestamp
Go: time.Time PG: timestamp with time zone PG-Short: timestamptz
Go: time.Time PG: time without time zone PG-Short: time
Go: time.Time PG: time with time zone PG-Short: timetz
diff --git a/loaders/postgres.go b/loaders/postgres.go
index a027c99..7cade4f 100644
--- a/loaders/postgres.go
+++ b/loaders/postgres.go
@@ -151,20 +151,13 @@ func PgParseType(args *internal.ArgType, dt string, nullable bool) (int, string,
typ = "byte"
case "date", "timestamp with time zone":
+ case "time with time zone", "time without time zone", "timestamp without time zone":
typ = "*time.Time"
if nullable {
nilVal = "pq.NullTime{}"
typ = "pq.NullTime"
}
- case "time with time zone", "time without time zone", "timestamp without time zone":
- nilVal = "0"
- typ = "int64"
- if nullable {
- nilVal = "sql.NullInt64{}"
- typ = "sql.NullInt64"
- }
-
case "interval":
typ = "*time.Duration"
This library looks really promising, thanks for sharing it.
How should we should handle columns holding timestamps that are maintained within the database, e.g:
CREATE OR REPLACE FUNCTION "Update_Modified_Column"() RETURNS TRIGGER AS '
BEGIN
NEW."Modified" = NOW();
RETURN NEW;
END;
' LANGUAGE 'plpgsql'
CREATE TABLE "MyTable" (
"ID" SERIAL PRIMARY KEY NOT NULL,
"SomeText" TEXT,
"Created" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP,
"Modified" TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP
)
CREATE TRIGGER "TR_MyTable_Update_Modified_Column" BEFORE UPDATE
ON "MyTable" FOR EACH ROW EXECUTE PROCEDURE
"Update_Modified_Column"()
In this case, I would prefer that the code generated by xo never inserted/update values in columns "Modified" or "Created". E.g. something like this would work:
--never-update "Modified","Created"
If your database table has a field named "type" or some other go reserved keyword and it's part of some index, then xo will name some local variables "type" which collides with the reserved keyword.
Some examples:
// ProductsByParentIDType retrieves a row from 'phx.products' as a Product.
//
// Generated from index 'products_parent_id_type'.
func ProductsByParentIDType(db XODB, parentID sql.NullInt64, type sql.NullString) ([]*Product, error) {
// ProductsBySkuIDType retrieves a row from 'phx.products' as a Product.
//
// Generated from index 'ku_id_type'.
func ProductsBySkuIDType(db XODB, sku sql.NullString, id int, type sql.NullString) ([]*Product, error) {
Renaming the variable from "type" to some other name ("t", for example) solves the problem.
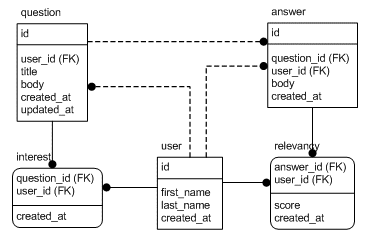
Viewing from a very high level, what xo currently does, is basically reverse-engine physical designs from the database to generate code.
What I hope is, someday xo can start not from reverse-engine physical databases, but from schema high level designs.
Take this ER diagram for example (taken from http://symfony.com/legacy/doc/askeet/1_0/en/2),
It can be expressed in high level in something like this (taken from http://symfony.com/legacy/doc/askeet/1_0/en/2):
propel:
_attributes: { noXsd: false, defaultIdMethod: none, package: lib.model }
ask_question:
_attributes: { phpName: Question, idMethod: native }
id: { type: integer, required: true, primaryKey: true, autoIncrement: true }
user_id: { type: integer, foreignTable: ask_user, foreignReference: id }
title: { type: longvarchar }
body: { type: longvarchar }
created_at: ~
updated_at: ~
ask_answer:
_attributes: { phpName: Answer, idMethod: native }
id: { type: integer, required: true, primaryKey: true, autoIncrement: true }
question_id: { type: integer, foreignTable: ask_question, foreignReference: id }
user_id: { type: integer, foreignTable: ask_user, foreignReference: id }
body: { type: longvarchar }
created_at: ~
ask_user:
_attributes: { phpName: User, idMethod: native }
id: { type: integer, required: true, primaryKey: true, autoIncrement: true }
nickname: { type: varchar(50), required: true, index: true }
first_name: varchar(100)
last_name: varchar(100)
created_at: ~
ask_interest:
_attributes: { phpName: Interest, idMethod: native }
question_id: { type: integer, foreignTable: ask_question, foreignReference: id, primaryKey: true }
user_id: { type: integer, foreignTable: ask_user, foreignReference: id, primaryKey: true }
created_at: ~
ask_relevancy:
_attributes: { phpName: Relevancy, idMethod: native }
answer_id: { type: integer, foreignTable: ask_answer, foreignReference: id, primaryKey: true }
user_id: { type: integer, foreignTable: ask_user, foreignReference: id, primaryKey: true }
score: { type: integer }
created_at: ~The syntax details is irrelevant, but my point is that YAML can express the tables, PK, FK, and relationships very clearly, in very high level. The physical design, and implementation details should be left to the code gen.
Just a wish.
Hello There,
Fantastic tool. Thank you so much for your effort. This is exactly what I needed.
I looked around, however could not find any further information on many-to-many and link table support. I was wondering if there is an early version I could play around with? This along with Postgres JSON support and an input query file for query generation are few of my biggest needs. Would deeply appreciate any guidance on when these may drop.
Thanks
I'm getting
error: exit status 2
when running xo now under go 1.6.
It appears to be generating all the models (this is a huge DB, there are 192 model files), but I'm not sure what the error is and if I should be worried or not. Running with -v shows this at the very end:
SQL:
SELECT seq_in_index AS seq_no, column_name FROM information_schema.statistics WHERE index_schema = ? AND table_name = ? AND index_name = ? ORDER BY eq_in_index
PARAMS:
[phoenix companies_before_add_refund_cols_to_companies idx_companies_on_updated_on]
error: exit status 2
Thank you.
Should use int32 instead
This is an easy one to report and, well, one that I can ignore pretty easily, but will impede Rails projects wanting to us xo. All Rails projects have a schema_migration table. Here's the MySQL description:
mysql> describe schema_migrations;
+---------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+--------------+------+-----+---------+-------+
| version | varchar(255) | NO | PRI | NULL | |
+---------+--------------+------+-----+---------+-------+
1 row in set (0.01 sec)
mysql> show index from schema_migrations;
+-------------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| schema_migrations | 0 | unique_schema_migrations | 1 | version | A | 661 | NULL | NULL | | BTREE | | |
+-------------------+------------+--------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
And here is the error go fmt gives on the output:
$ go fmt schemamigration.xo.go
schemamigration.xo.go:93:16: expected operand, found ','
schemamigration.xo.go:95:2: missing ',' in argument list
schemamigration.xo.go:96:1: expected operand, found '}'
schemamigration.xo.go:100:2: missing ',' in argument list
schemamigration.xo.go:101:3: expected operand, found 'return'
schemamigration.xo.go:102:2: expected operand, found '}'
schemamigration.xo.go:104:2: missing ',' in argument list
schemamigration.xo.go:105:1: expected operand, found '}'
schemamigration.xo.go:109:2: missing ',' in argument list
schemamigration.xo.go:112:2: missing ',' in argument list
schemamigration.xo.go:113:3: expected operand, found 'return'
Similar to #14 . Identical?
The naming collision occurs although if one field is named after another table.
CREATE TABLE account (
id BIGSERIAL PRIMARY KEY,
name text UNIQUE NOT NULL
);
CREATE TABLE session (
id BIGSERIAL PRIMARY KEY,
account bigint REFERENCES "account" (id) NOT NULL
);The SQL above generates:
type Session struct {
ID int64 `json:"id"` // id
Account int64 `json:"account"` // account
...
}
func (s *Session) Account(db XODB) (*Account, error) {
return AccountByID(db, s.Account)
}This leads to a collision: models/session.xo.go:160: type Session has both field and method named Account
Is it possible to detect this collisions and handle them?
Like --fk-mode field does?
This leads to usable code.
-// Account returns the Account associated with the Session's Account (account).
+// AccountByAccount returns the Account associated with the Session's Account (account).
//
// Generated from foreign key 'session_account_fkey'.
-func (s *Session) Account(db XODB) (*Account, error) {
+func (s *Session) AccountByAccount(db XODB) (*Account, error) {
return AccountByID(db, s.Account)
}Since this is a model between the database and the application it would make sense for XO to add a flag option for adding for sql.ErrNoRows to models which return a single struct.
This is a relatively simple fix (using a marker in the Template) which changes
err = db.QueryRow(sqlstr, x).Scan(....)
if err != nil {
return nil, err
}
Into this:
err = db.QueryRow(sqlstr, x).Scan(....)
if err != nil {
// there was no row, but otherwise no error occurred
if err == sql.ErrNoRows {
return nil, nil
}
return nil, err
}
Then the application can just check that they get something back (if Foo != nil) rather than needing to add this additional check every place the model is used.
In the event that fields match methods the generator should prefix struct fields with Is or something similar.
I use xo executable under Linux to access Microsoft SQL Server under Microsoft Windows and generated the models just fine. Just that the tables are named booktest. something to dbo. something. E.g., in author.xo.go, here are part of the changes:
@@ -1,2 +1,2 @@
-// Package models contains the types for schema 'booktest'.
+// Package models contains the types for schema 'dbo'.
package models
@@ -7,3 +7,3 @@
-// Author represents a row from 'booktest.authors'.
+// Author represents a row from 'dbo.authors'.
type Author struct {
@@ -36,3 +36,3 @@
// sql query
- const sqlstr = `INSERT INTO booktest.authors (` +
+ const sqlstr = `INSERT INTO dbo.authors (` +
`name` +
@@ -77,3 +77,3 @@
// sql query
- const sqlstr = `UPDATE booktest.authors SET ` +
+ const sqlstr = `UPDATE dbo.authors SET ` +
This is more correct for Microsoft SQL Server, because in it, to access a table, it should normal be booktest.dbo.authors, or booktest..authors, or dbo.authors.
However, when run the built code from the generated the models, I get the error of:
2017/01/05 11:46:47 mssql: Invalid object name 'booktest.authors'.
This is strange because I don't know where the booktest.authors is coming from:
$ grep -ir authors *
models/authorbookresult.xo.go: `JOIN authors a ON a.author_id = b.author_id ` +
models/author.xo.go:// Author represents a row from 'dbo.authors'.
models/author.xo.go: const sqlstr = `INSERT INTO dbo.authors (` +
models/author.xo.go: const sqlstr = `UPDATE dbo.authors SET ` +
models/author.xo.go: const sqlstr = `DELETE FROM dbo.authors WHERE author_id = $1`
models/author.xo.go:// AuthorByAuthorID retrieves a row from 'dbo.authors' as a Author.
models/author.xo.go:// Generated from index 'PK__authors__86516BCF3EE7ECFC'.
models/author.xo.go: `FROM dbo.authors ` +
models/author.xo.go:// AuthorsByName retrieves a row from 'dbo.authors' as a Author.
models/author.xo.go:// Generated from index 'authors_name_idx'.
models/author.xo.go:func AuthorsByName(db XODB, name string) ([]*Author, error) {
models/author.xo.go: `FROM dbo.authors ` +
I.e., no where in my code under mssql folder has the booktest.authors string and all of them are of form dbo.authors.
What's wrong? Thx.
Whene a table is called time, a type Time is created and all timerelated columns are mapped to it. For example. For example:
CREATE TABLE `times` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`date` date NOT NULL,
`start` time DEFAULT NULL,
`end` time DEFAULT NULL,
`project` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`txt` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=648 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ciproduces:
type Time struct {
ID int `json:"id"` // id
Date *time.Time `json:"date"` // date
Start Time `json:"start"` // start
End Time `json:"end"` // end
Project sql.NullString `json:"project"` // project
Txt sql.NullString `json:"txt"` // txt
// xo fields
_exists, _deleted bool
}Start and End should be *mysql.NullTime or *time.Time in case of NOT NULL.
Using sqlite the following schema
CREATE TABLE authors (
author_id integer NOT NULL PRIMARY KEY,
name text NOT NULL DEFAULT ''
);results in
type Author struct {
AuthorID int // author_id
Name string // name
// xo fields
_exists, _deleted bool
}while
CREATE TABLE authors (
author_id INTEGER NOT NULL PRIMARY KEY,
name text NOT NULL DEFAULT ''
);results in
type Author struct {
AuthorID string // author_id
Name string // name
// xo fields
_exists, _deleted bool
}Context: we have several instances of the same database schema, under different schema names in a single MySQL installation. We would like to be able to switch between them just by changing the schema in the connection string we pass to our binary in a flag.
Problem: This doesn't seem possible with xo at the moment because it adds the schema to all table and proc names in the generated code. Switching between different schemas requires re-generating the xo code and re-compiling.
Possible solution?: New flag to disable schema concatenation in internal.schmafn. More than happy to send a pull request if this sounds reasonable.
Current: UPDATE dev.User SET
Desired: UPDATE User SET
I am getting the following error when I run xo. This is on PostgreSQL 9.5.3
error: could not find public.safc_illness_injury_cause index safc_illness_injury_cause_ux1 column id 0
Here is my table structure from pgAdmin
`CREATE TABLE public.safc_illness_injury_cause
(
pk integer NOT NULL DEFAULT nextval('safc_illness_injury_cause_pk_seq'::regclass),
company_pk integer NOT NULL,
illness_injury_cause character varying NOT NULL,
created_on timestamp with time zone,
updated_on timestamp with time zone,
created_by text,
updated_by text,
CONSTRAINT safc_illness_injury_cause_pkey PRIMARY KEY (pk),
CONSTRAINT safc_illness_injury_cause_company_pk_fkey FOREIGN KEY (company_pk)
REFERENCES public.app_company (pk) MATCH SIMPLE
ON UPDATE CASCADE ON DELETE CASCADE
)
WITH (
OIDS=FALSE
);
ALTER TABLE public.safc_illness_injury_cause
OWNER TO mana;
CREATE INDEX safc_illness_injury_cause_ix1
ON public.safc_illness_injury_cause
USING btree
(company_pk);
CREATE UNIQUE INDEX safc_illness_injury_cause_ux1
ON public.safc_illness_injury_cause
USING btree
(company_pk, lower(illness_injury_cause::text) COLLATE pg_catalog."default");
CREATE TRIGGER trgb_safc_illness_injury_cause_timestamp
BEFORE INSERT OR UPDATE
ON public.safc_illness_injury_cause
FOR EACH ROW
EXECUTE PROCEDURE public.fn_trigb_update_timestamp();`
Thanks.
Using MSSQL Driver from https://github.com/denisenkom/go-mssqldb.git
Getting this trying this from CLI.
xo mssql://user:pass@host:1433/db -o models -N -M -B -T Match << ENDSQL
select * from match ;
ENDSQL
error: sql: Scan error on column index 0: unsupported driver -> Scan pair: -> *string
Is there another driver I should be using?
Thanks.
When two tables in a MySQL database have enum columns with the same name, the created constants might colide.
This can be fixed by using the following queries.
In MyEnums:
const sqlstr = `SELECT ` +
`DISTINCT CONCAT("enum_", table_name, "_", column_name) AS enum_name ` +
`FROM information_schema.columns ` +
`WHERE data_type = 'enum' AND table_schema = ?`In MyEnumValue:
const sqlstr = `SELECT ` +
`SUBSTRING(column_type, 6, CHAR_LENGTH(column_type) - 6) AS enum_values ` +
`FROM information_schema.columns ` +
`WHERE data_type = 'enum' AND table_schema = ? AND CONCAT("enum_", table_name, "_", column_name) = ?`This will avoid colissions between enums and enums as well as enums and tables
Hi, it seems that test do not use created transactions.
You have:
tx, err := db.Begin()
and later on
err = b0.Save(db)
instead of
err = b0.Save(tx)
Also, there should be a defered rollback i suppose.
Hey @kenshaw. I'm keen to add support for Postgres comments on tables and columns etc. I see the readme has
Finish COMMENT support for PostgreSQL/MySQL and update templates accordingly.
but I can't find any the existing work on the feature.
Has this been started? If not, I'd like to take a crack at it if you're happy to look at a PR for this.
Thanks for the great tool!
the xo developers are of the opinion that relational databases should have proper, well-designed relationships and all the related definitions should reside within the database schema itself -- call it "self-documenting" schema. xo is an end to that pursuit
Totally agree. However, I hope thing will not ends there, but bring the documenting to the next level -- using E-R diagrams. Since xo has already had a clear view of the table, PK, FK and their relationships, dumping out such relationships should not be too difficult.
And I hope the Dot format from GraphViz is one of the output format. It can be more beautiful than people normally think -- check out https://github.com/BurntSushi/erd for example.
thanks
Any plan to add checking exist on index in xo?
Other than returning all rolls for an index (feature generated by xo), many times, people just want to checking the existence of the index key, and count maybe as well.
Any plan to add generated code for it/them? Thx.
I've only tested this with PostgreSQL (9.5), so I don't know if this affects other DBs.
When I have a schema of:
CREATE TABLE parent (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL);
CREATE TABLE child (
blah TEXT;
) INHERITS (parent);
When using xo to generate code, it generates Insert/Update/Delete/Upsert/etc functions for "parent" table, but not for "child" table. Is there a way to force this? At the moment, I have to copy, paste and modify the parent functions to use in child.xo.go
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.