Project Website with Demo Video.
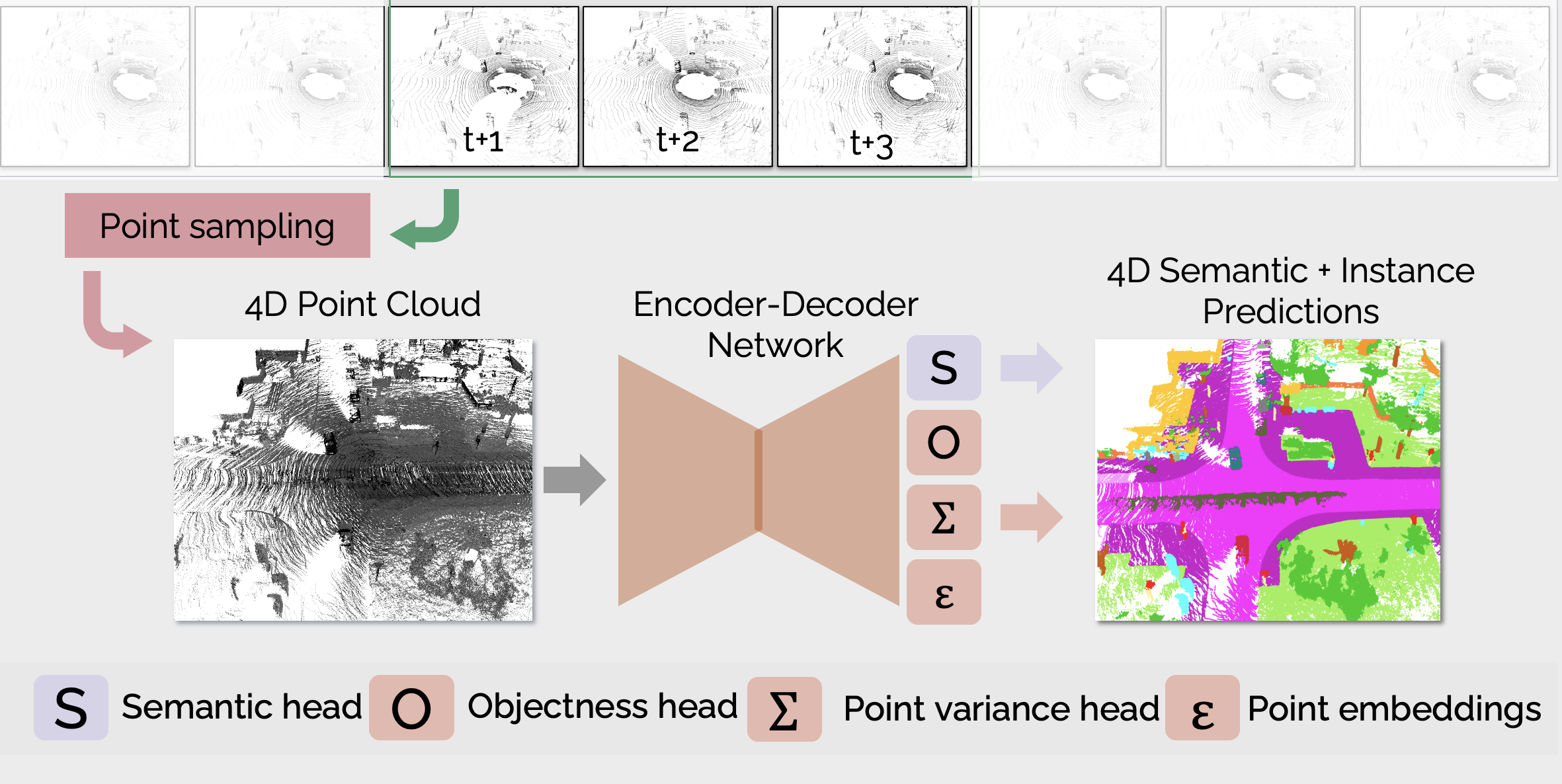
This repo contains code for the paper 4D Panoptic Lidar Segmentation. The code is based on the Pytoch implementation of KPConv.
git clone https://github.com/MehmetAygun/4D-PLS
cd 4D-PLS
pip install -r requirements.txt
cd cpp_wrappers
sh compile_wrappers.shCreate a directory data in main directory, download the SemanticKitti to there with labels from here
Also add semantic semantic-kitti.yaml file in SemanticKitti folder, you can download the file from here
Then create additional labels using utils/create_center_label.py,
python create_center_label.pyThe data folder structure should be as follows:
data/SemanticKitti/
└── semantic-kitti.yaml
└── sequences/
└── 08/
└── poses.txt
└── calib.txt
└── times.txt
└── labels
├── 000000.label
...
└── velodyne
├── 000000.bin
...
For saving models or using pretrained models create a folder named results in main directory.
You can download a pre-trained model from here .
For training, you should modify the config parameters in train_SemanticKitti.py.
The most important thing that, to get a good performance train the model using config.pre_train = True firstly at least for 200 epochs, then train the model using config.pre_train = False.
python train_SemanticKitti.pyThis code will generate config file and save the pre-trained models in the results directory.
For testing, set the model directory the choosen_log in test_models.py, and modify the config parameters as you wish. Then run :
python test_models.pyThis will generate semantic and instance predictions for small 4D volumes under the test/model_dir.
To generate long tracks using small 4D volumes use stitch_tracklets.py
python stitch_tracklets.py --predictions test/model_dir --n_test_frames 4This code will generate predictions in the format of SemanticKITTI under test/model_dir/stitch .
For getting the metrics introduced in the paper, use utils/evaluate_4dpanoptic.py
python evaluate_4dpanoptic.py --dataset=SemanticKITTI_dir --predictions=output_of_stitch_tracket_dir --data_cfg=semantic-kitti.yamlIf you find the code useful in your research, please consider citing:
@InProceedings{aygun20214d,
author = {Aygun, Mehmet and Osep, Aljosa and Weber, Mark and Maximov, Maxim and Stachniss, Cyrill and Behley, Jens and Leal-Taixe, Laura},
title = {4D Panoptic LiDAR Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {5527-5537}
}
GNU General Public License (http://www.gnu.org/licenses/gpl.html)
Copyright (c) 2021 Mehmet Aygun Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.














































































































